Evaluations
The evaluation module enables you to conduct automated tests on your bots, ensuring optimal performance and identifying potential issues.
Overview
Evaluations leverage a Large Language Model (LLM) as a technical judge. For each user question in the test set, the module compares the bot's actual response with the expected answer. This approach helps:
- Prevent regressions.
- Assess model and prompt performance.
- Track improvements over time.
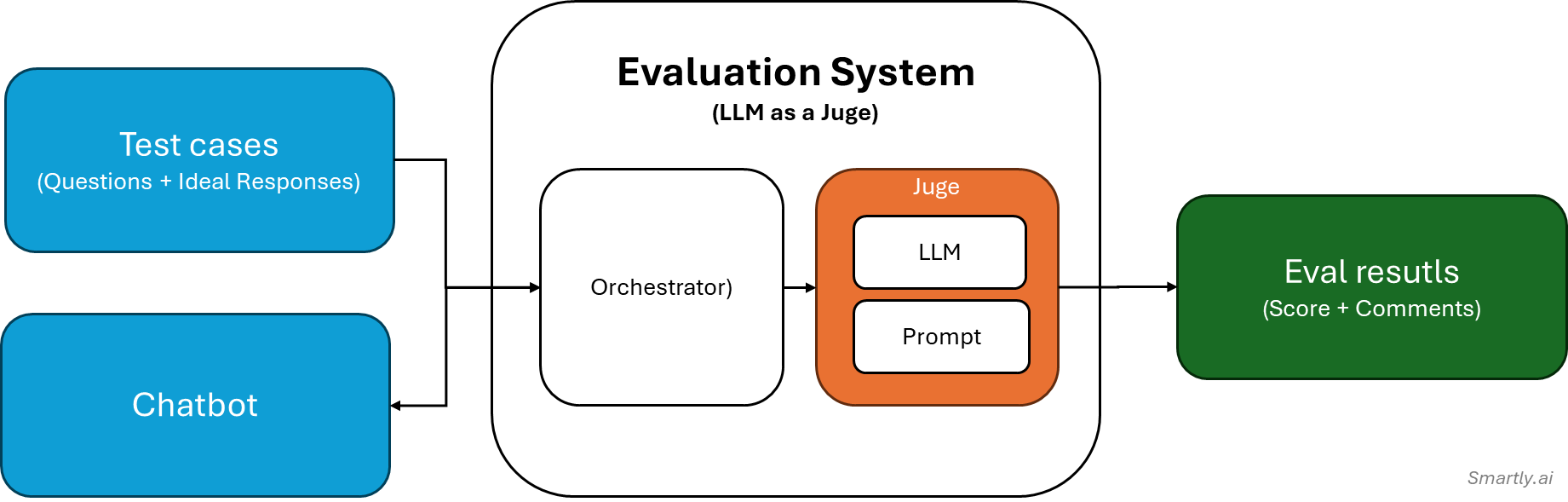
This illustration below shows how the LLM Evaluation Metric works:
- Input: Test case data (e.g., user query, LLM output, context) is provided.
- Scoring: The LLM Judge Scorer evaluates the response, generating a score and optional reasoning.
- Threshold Check: The score is compared to a threshold to determine if the test passes (✅) or fails (❌).
Steps to Use the Evaluation Module
1. Create an Evaluation Set
An evaluation set consists of:
- Questions: User queries to test the bot.
- Ideal Answers: Expected responses for each query.
You can create as many Q&A pairs as needed. Additionally, you can import or export these pairs in CSV format for easier management.
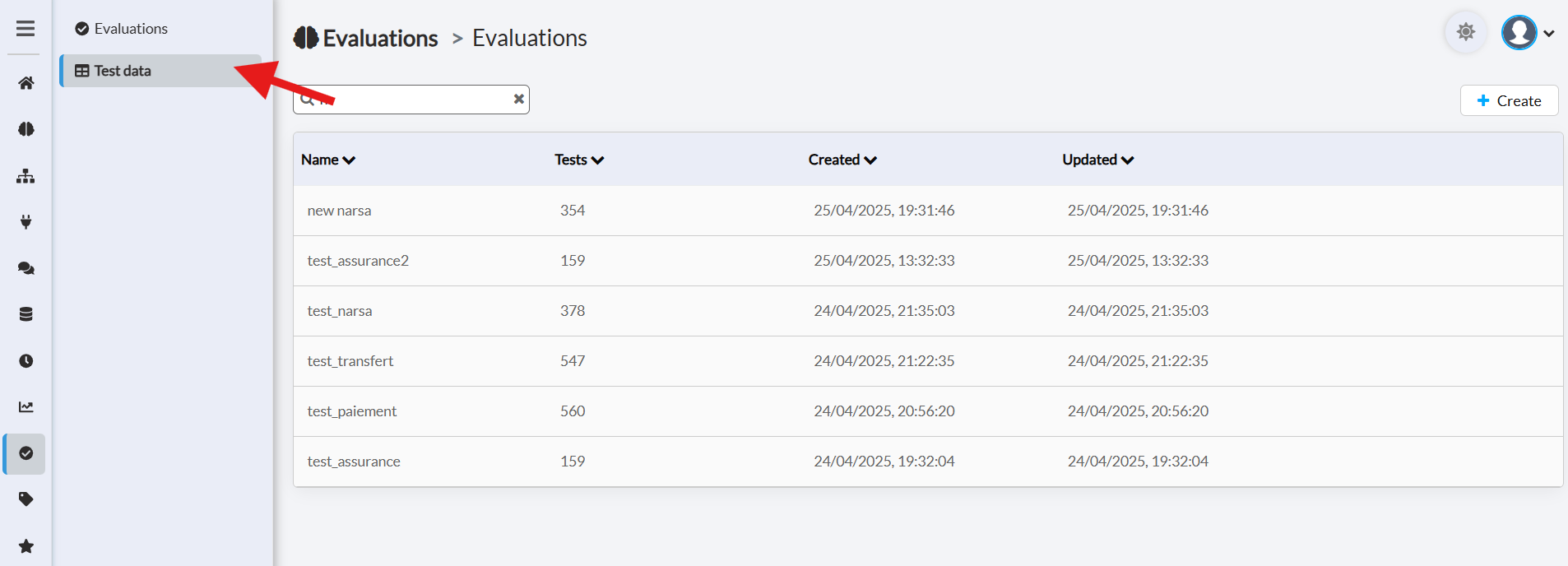
The Test Data section
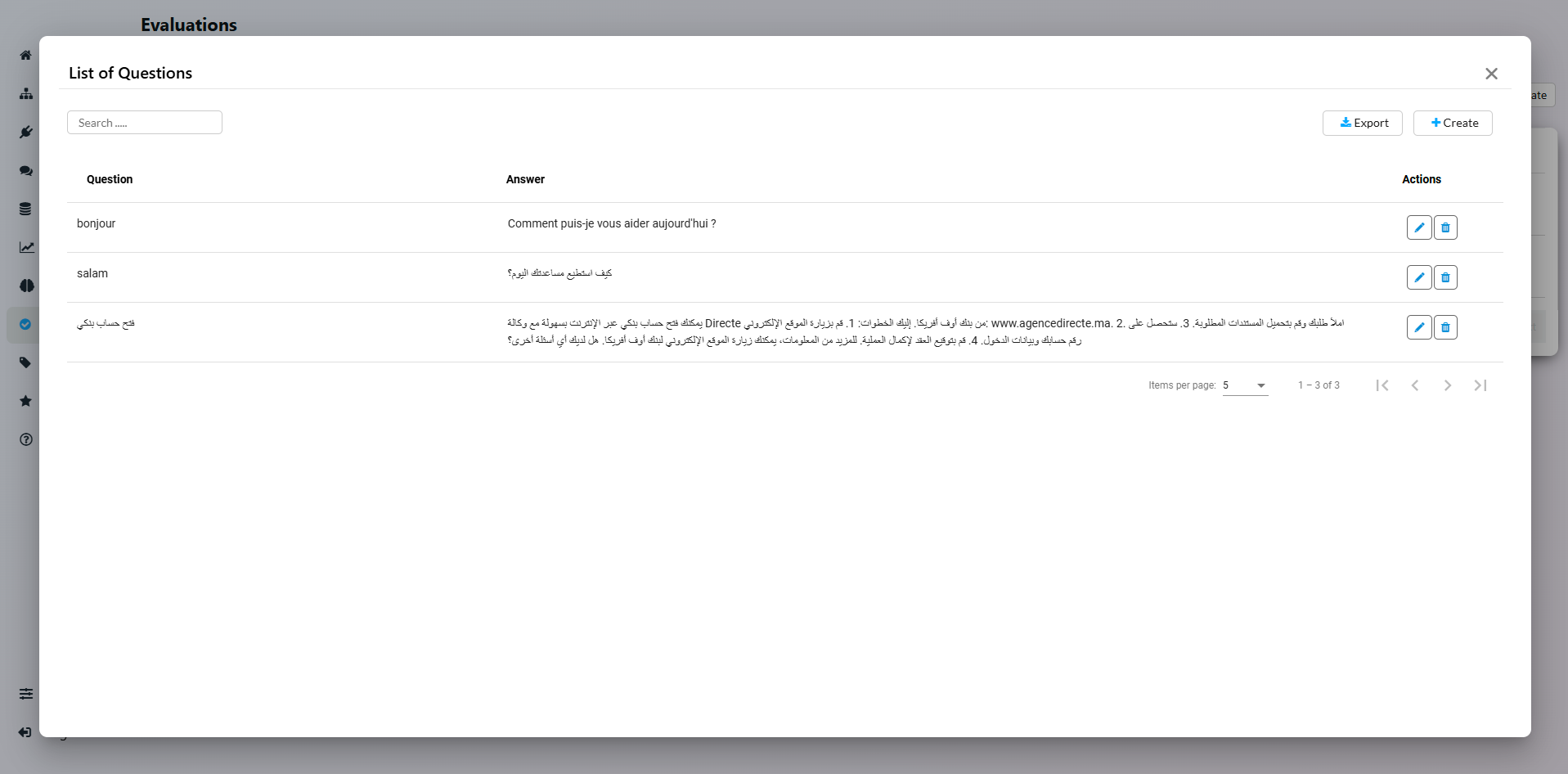
The Test Cases view is basically a Question / Answer list
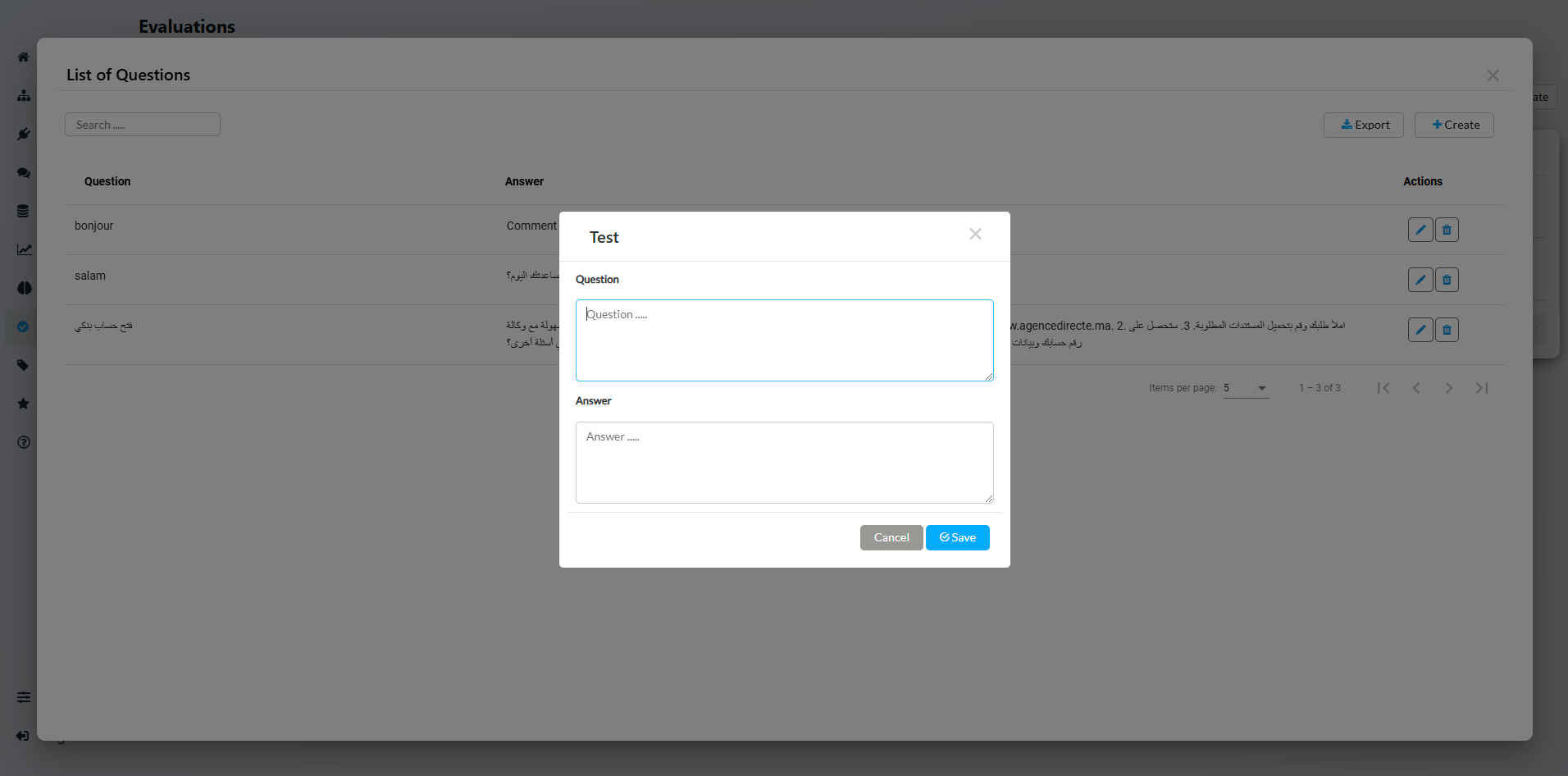
You can Edit each test case if needed
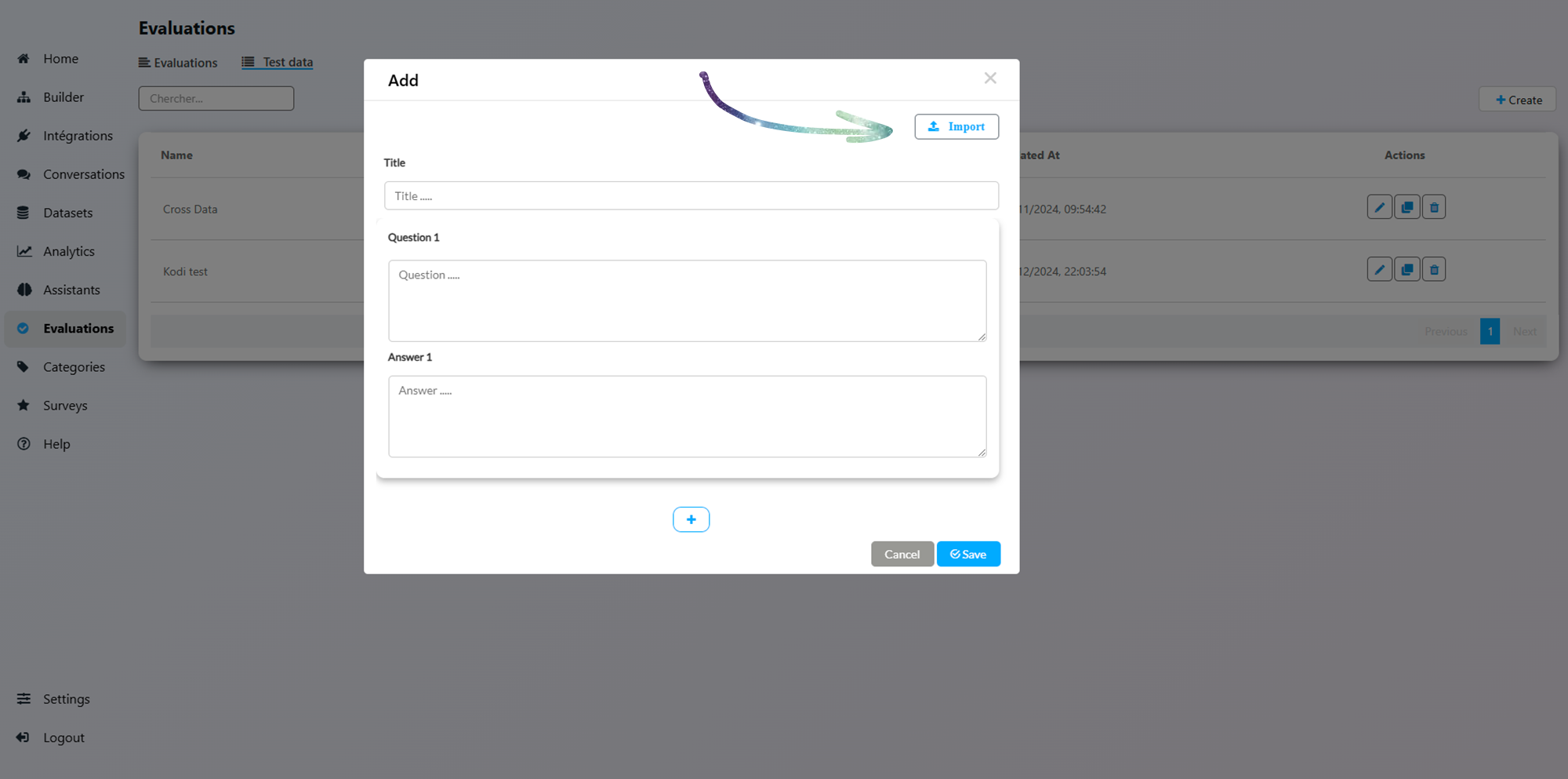
Use the Import / Export feature to handle big datasets
2. Configure an Evaluation
To create a new evaluation run, click the + Create button.
This will open the configuration window where you need to provide the following details:
- Bot to Evaluate: The specific bot you want to test.
- Evaluation Set: Select the test set created earlier.
- AI Deployment: Specify the AI configuration to evaluate.
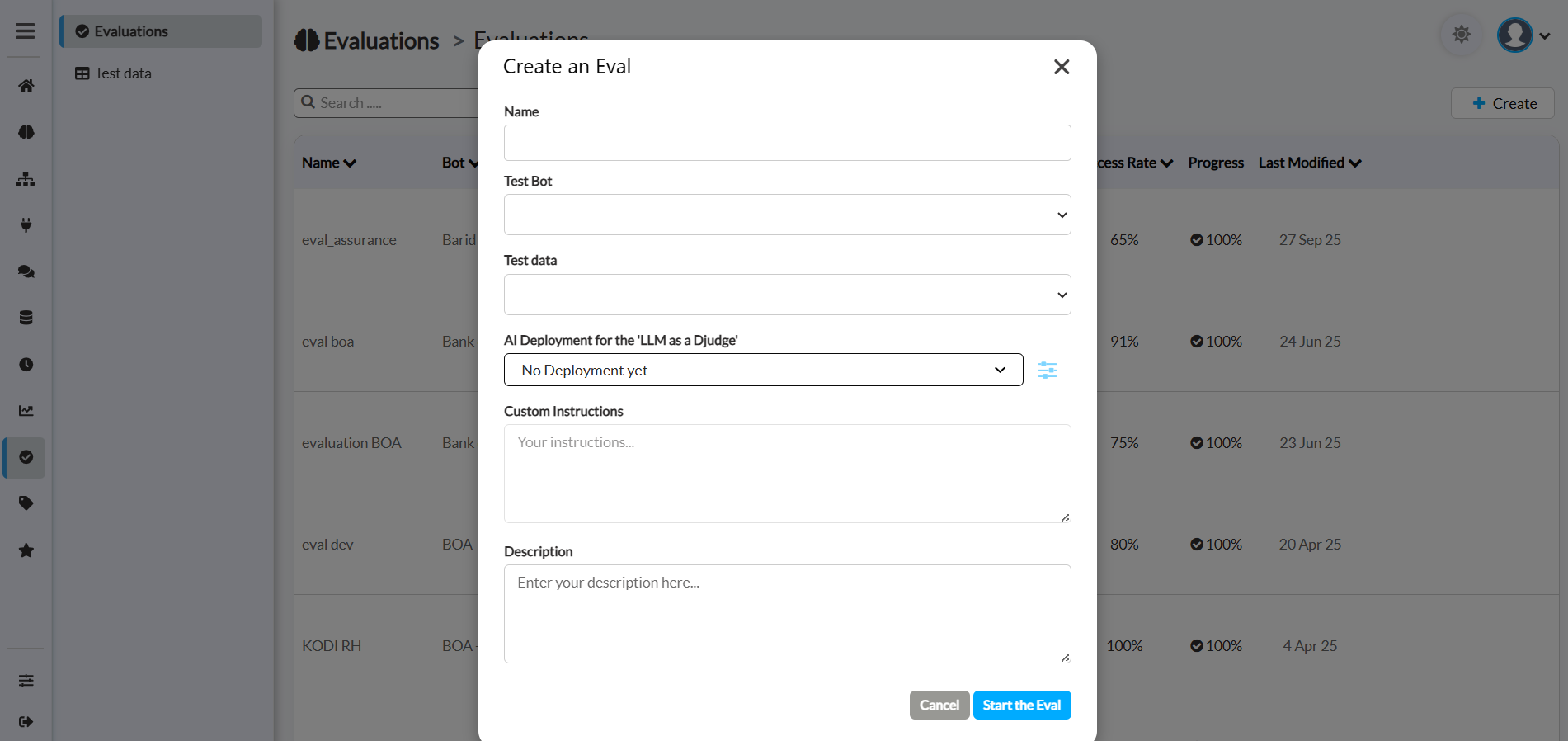
- Name: Enter a unique name for this evaluation test. This will help you identify it later.
- Test Bot: Select the specific bot you want to evaluate from the dropdown list.
- Test data: Choose the evaluation dataset you created earlier. This dataset contains the questions that will be asked to the bot and the reference answers to compare against.
- AI Deployment for the 'LLM as a Judge': Select an AI Deployment that will act as the automated "judge." This powerful feature uses an LLM to programmatically compare the test bot's answers to the reference answers in your test data.
- Custom Instructions: Provide specific instructions to the 'LLM Judge' to guide its evaluation process. This is a very powerful field that allows you to tailor the scoring criteria.
- Description: Add a description for this evaluation. This is useful for your own records to remember the purpose of a specific test run.
Once configured, the evaluation will run automatically.
Managing and Analyzing Evaluations
After you have created and run an evaluation, the main Evaluations dashboard becomes your central hub for tracking, comparing, and analyzing the performance of your bots.
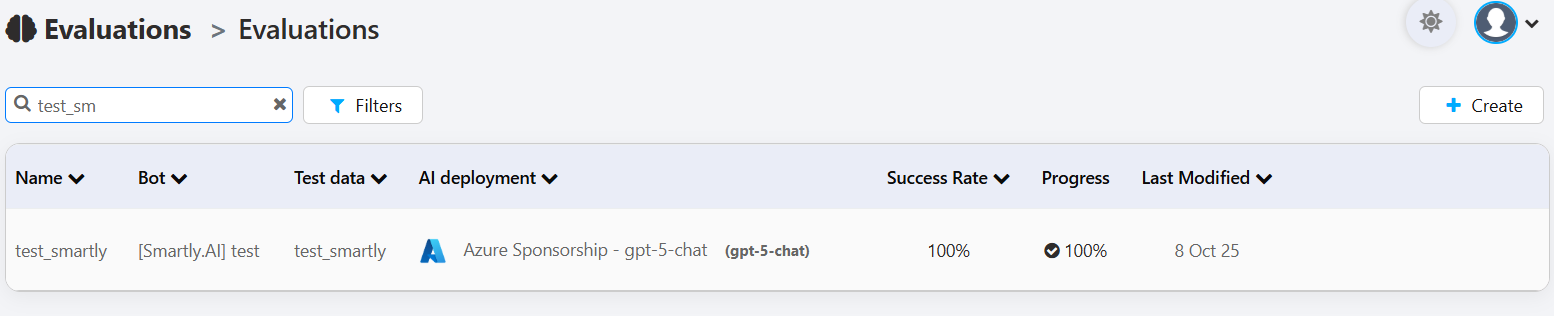
Understanding the Evaluations List
The dashboard displays a list of all your evaluation runs. Each row provides a summary of a specific test:
- Name: The unique name you gave to the evaluation run.
- Bot: The bot that was tested.
- Test data: The specific dataset of questions and reference answers that was used.
- AI deployment: The AI model configuration that was evaluated. This is crucial for comparing the performance of different models or settings.
- Success Rate: The final score of the evaluation, representing the percentage of the bot's answers that were judged as successful based on your criteria.
- Progress: The status of the evaluation. A checkmark and "100%" indicates that the run is complete.
- Last Modified: The date the evaluation was last run or modified.
Managing Completed Evaluations
Once an evaluation is complete, a set of action buttons appears on the right side of its row, allowing you to work with the results:
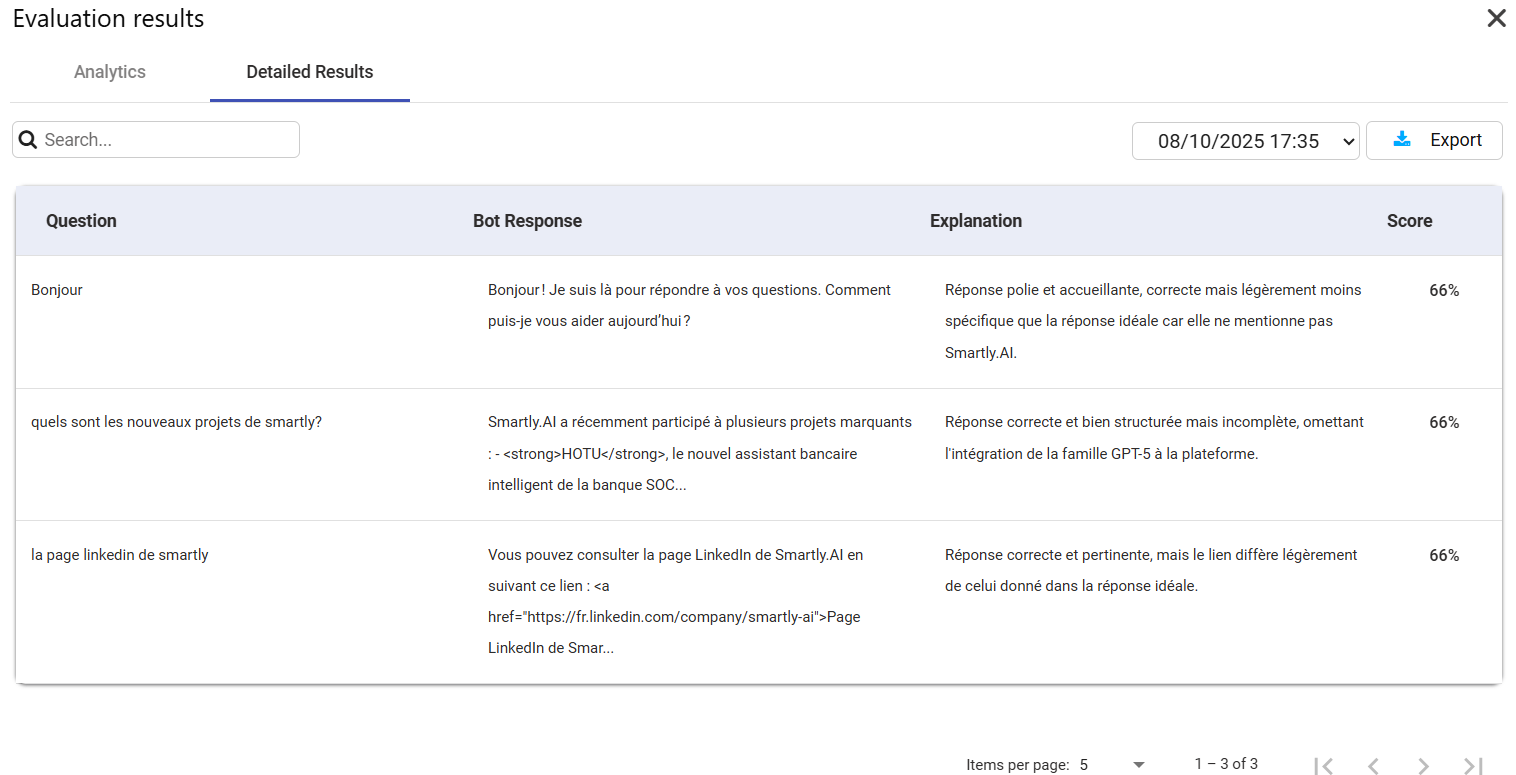
📁 View Results: This is the most important action. It opens a detailed report where you can see a question-by-question breakdown of the evaluation. You can compare the bot's generated answer, the reference answer from your test data, and the score given by the "LLM Judge" for each item.
Viewing and Managing Results
After the evaluation completes, you can:

📁 View Results: This is the most important action. It opens a detailed report where you can see a question-by-question breakdown of the evaluation. You can compare the bot's generated answer, the reference answer from your test data, and the score given by the "LLM Judge" for each item.
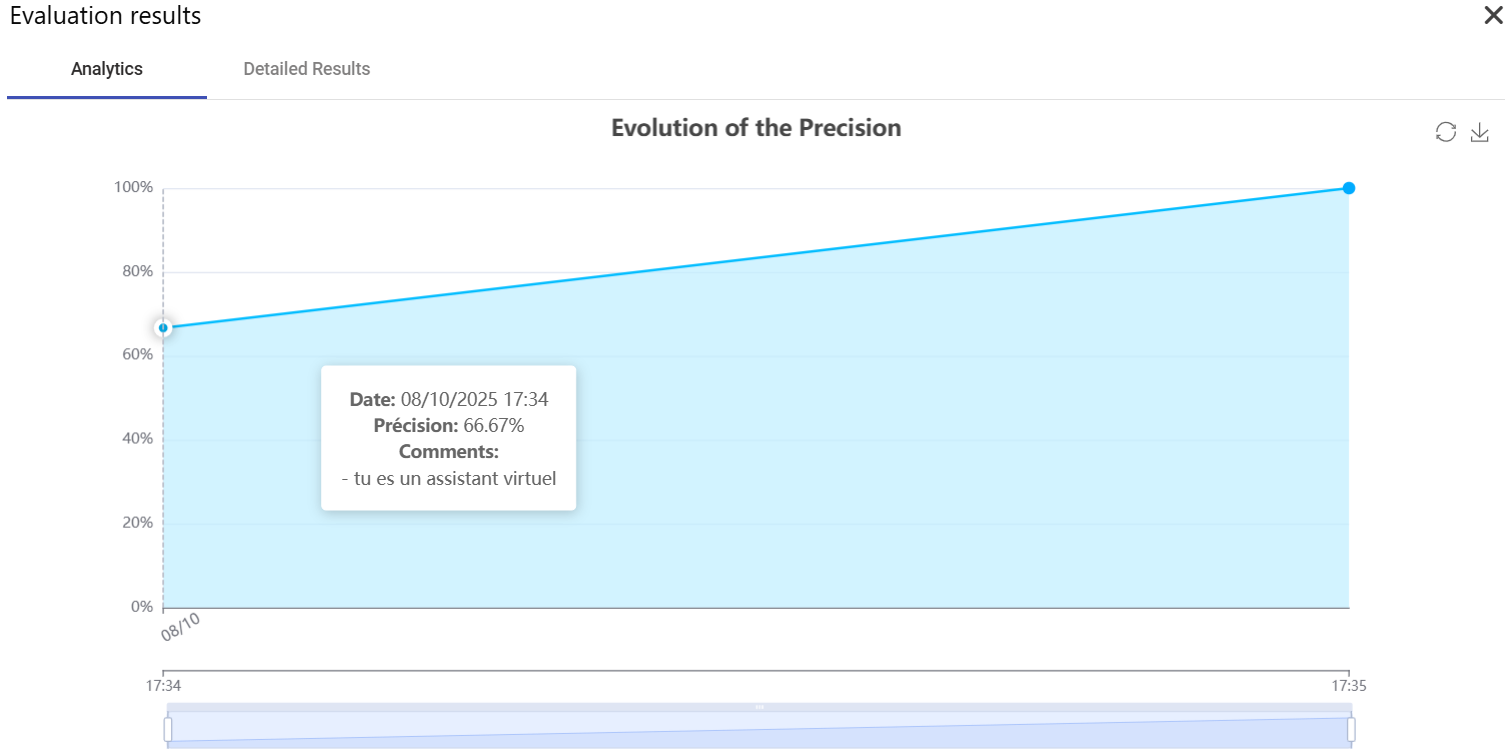
Analyze Trends: View bot accuracy trends in a chart format.
🔄 Relaunch Evaluation: This runs the exact same test again. This is very useful for verifying results or for running an A/B test after you've made a small change to the bot's configuration or prompt.
You can rerun evaluations at any time. For each rerun:
- You’ll be prompted to provide a comment describing changes made to the bot or its configuration.
- These comments serve as a log to track the impact of modifications over time.
While reviewing the detailed results, you can select the date and time to compare the pas results.
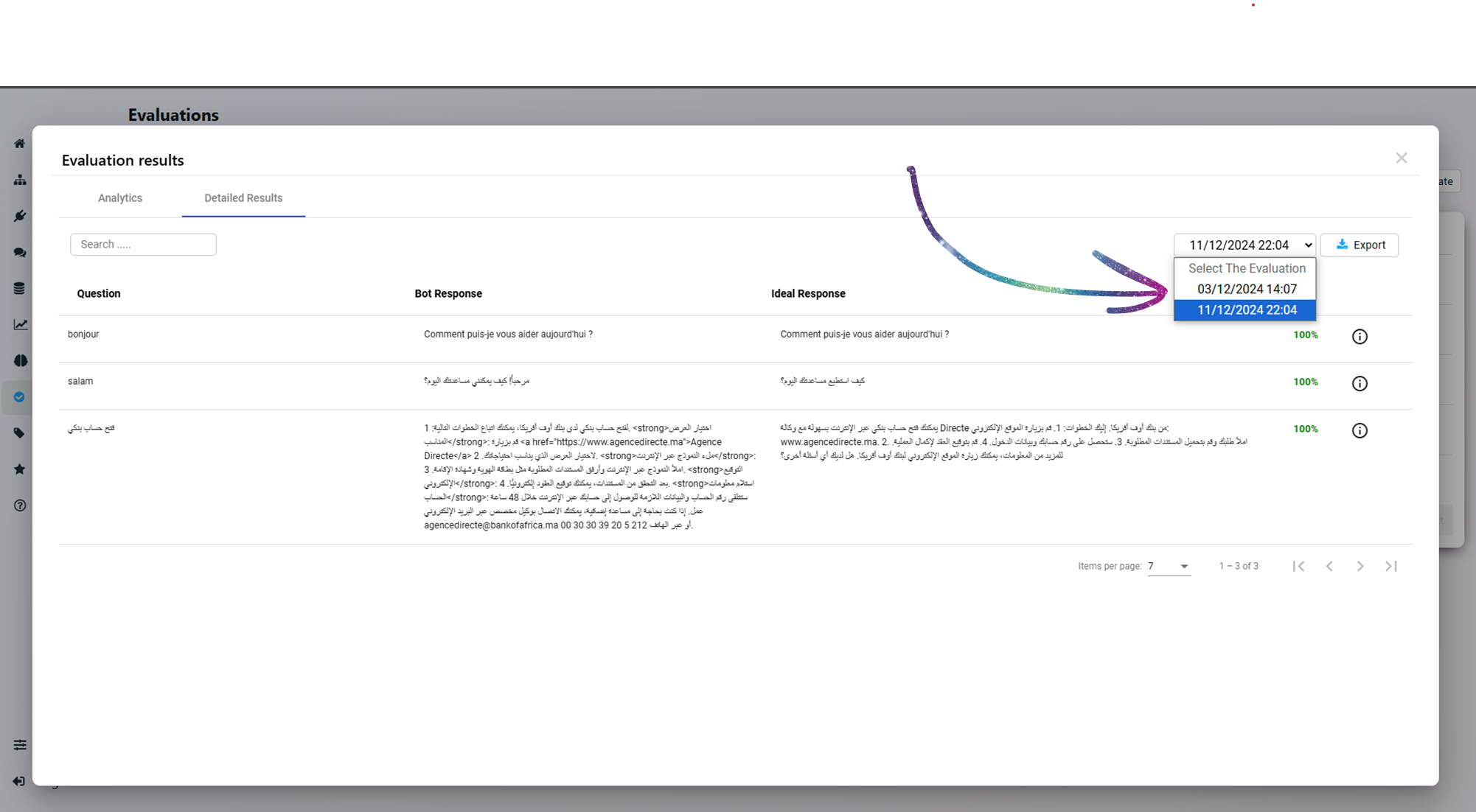
You can select past evaluatoins to compare / export the results
⬇️ Download: This allows you to export the detailed evaluation results as a file (e.g., CSV or JSON) for offline analysis or for sharing with your team.
🗑️ Delete: This permanently removes the evaluation run and its associated results from the list.