Knowledge bases
The knowledge base is the brain of your bot. This is where you centralize all the information it will use to provide accurate and relevant answers to user questions.
What is a Knowledge Base?
It is the collection of all data in which your assistant can search for answers. It powers the AI engine.
What is a Data Source?
A data source is a document, web page, or specific text that you provide. All of your data sources together make up your knowledge base.
Create and Configure a Knowledge Base
To create a new knowledge base, click the "+ Create" button. A configuration window will open, guiding you through the different options.
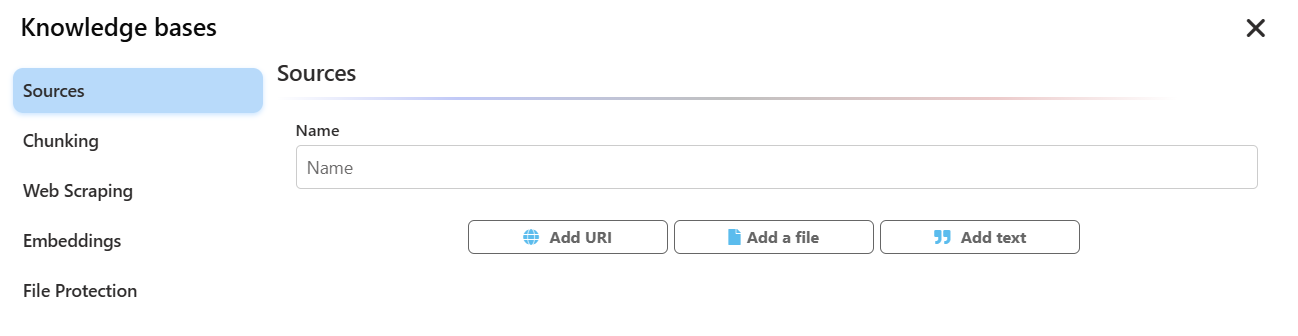
- Name: Give your knowledge base a clear and descriptive name so you can easily find it.
- Sources: This is where you add content. You can populate your knowledge base with several types of sources:
- Add URI (Web Content): Allows you to add web pages by providing their URLs. The system will "scrape" the content from these pages. If you have a large website, you can simply add a parent URL and use a search function to automatically extract links to child pages, saving you considerable time.
- Add a File (Uploaded Files): You can upload documents in PDF, DOC, CSV, and TXT formats. Our system also includes an OCR (Optical Character Recognition) algorithm that can extract text from images or scanned documents in PNG or JPG formats.
- Add Text (Plain Text): Allows you to copy and paste plain text directly into a data source.
Limits: You can attach up to 50 knowledge bases per assistant, and each knowledge base can contain up to 5,000 data sources.
What if I have a big website with many pages?
Managing a large website with multiple pages can be challenging, but we've made it simpler for you. To add your extensive web content into your Knowledge Base, just do the following:
- Add a 'Web Content' data source to your Knowledge Base.
- Click on the "Search URLs" button.
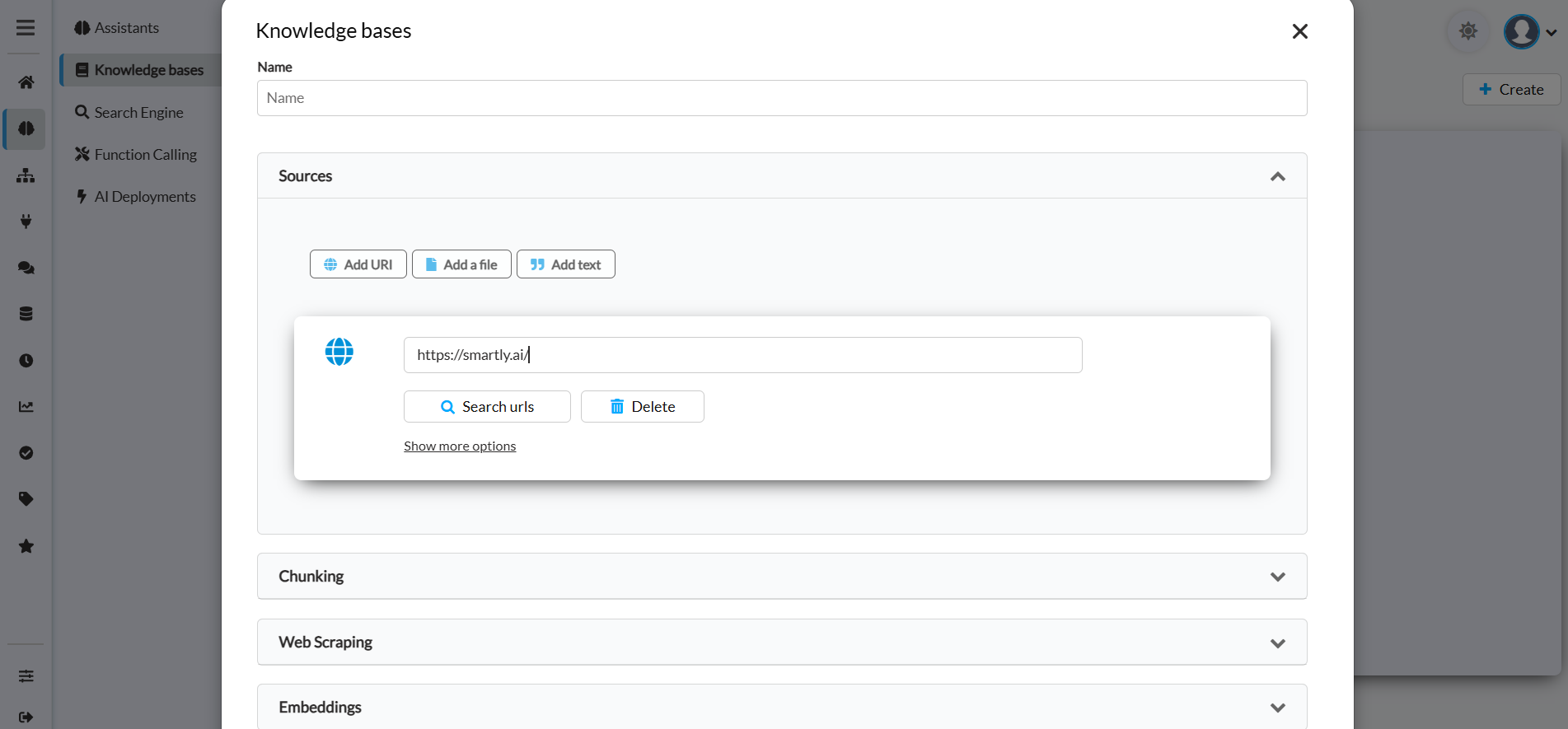
Add a parent page and click "Search urls"
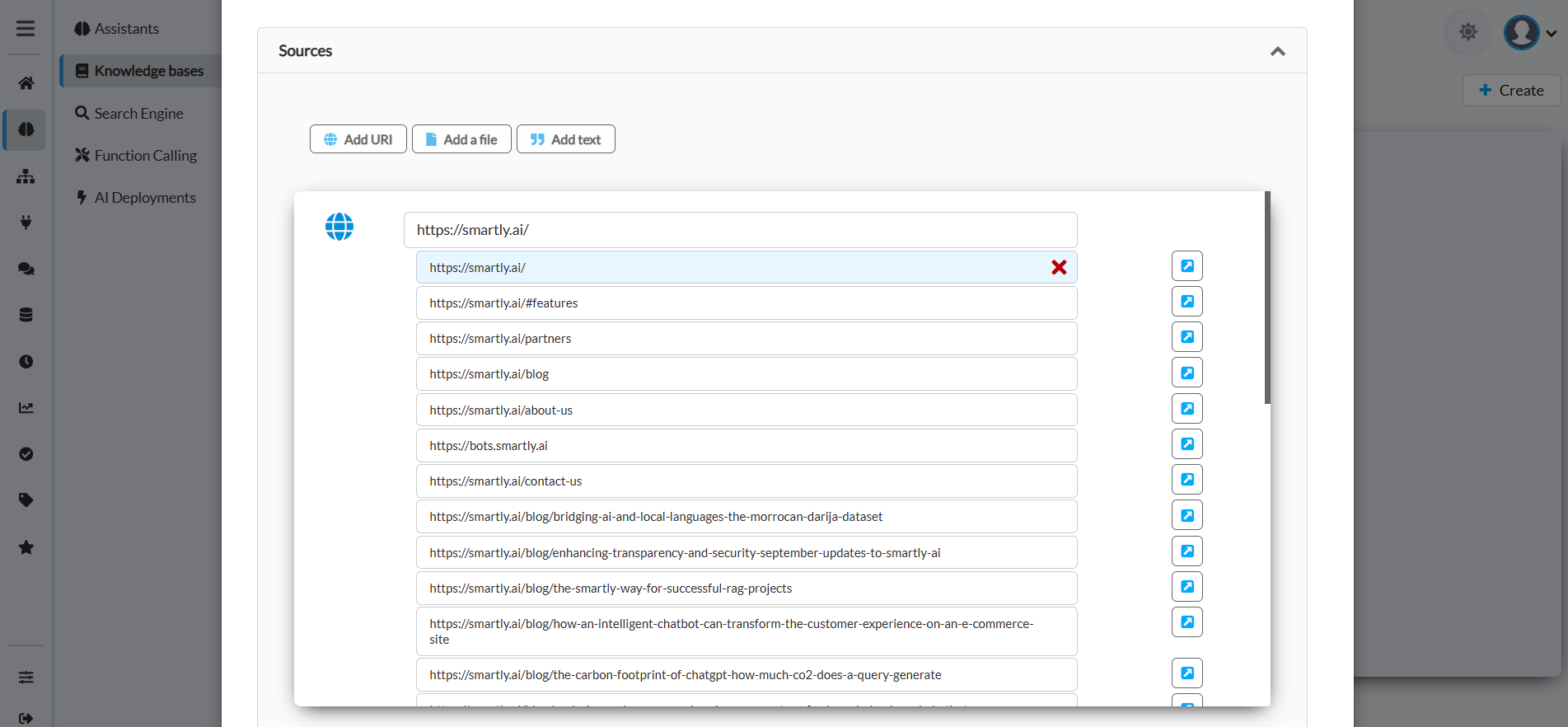
Results populate within the associated parent folder, allowing you to selectively keep or remove URLs as needed
This action will automatically extract all the URLs from the designated web pages, saving you significant time. Once the URL list is generated, you have the option to remove any URLs that are not relevant by clicking on the 'Delete' button. By extracting URLs from key pages of your website, you can swiftly map out your website's essential content in your Knowledge Base. Rest assured, duplicate URLs are not an issue; they will be ignored during the training phase.
What if I have a scanned document?
If you have scanned documents to include in your Knowledge Base, fret not. The Smartly platform is equipped with cutting-edge OCR (Optical Character Recognition) algorithms that can extract text from image-based documents. To take advantage of this feature, simply add your scanned document as a PNG or JPG file in your data sources. Our cutting-edge OCR technology will then automatically process these files to extract and index the text, making it a part of your assistant's Knowledge Base.

Smartly.AI OCR (Optical Character Recognition)
What happens to my data sources?
Your data sources undergo several processes:
- Ingestion (Web scraping for web content, OCR for scanned docs)
- Cleaning
- Splitting
- Vectorization (via embeddings)
- Storage in a local vector store
After defining your data sources, click on the Train button to update your Knowledge Base with the new content. Once ingested and processed, the Knowledge Base will be used by the bot to answer user questions.
Advanced Settings
These sections, presented as accordions, allow you to refine how your data is processed.
Chunking
When adding a file, it is crucial to split it into smaller segments so the AI can analyze them effectively. This step is called "Chunking". There are two main methods:
a. Page-based Chunking (for PDF files only):
- Principle: This option, available only for PDF files, transforms each page of the document into a separate segment.
- Example: If you have a 2-page PDF, after indexing, the platform will create 2 separate sections, each containing the information from a single page.
b. Uniform Chunking:
- Principle: This method, applicable to all types of text sources, allows you to precisely define the size of your segments using two parameters:
- Number of characters per segment: The maximum size of each text chunk.
- Number of overlapping characters: The number of characters from the end of one segment that will be repeated at the beginning of the next segment.
Why is overlapping important?
It acts as a "stitch" between segments. This prevents abrupt cuts in the middle of sentences or ideas and ensures that context is preserved, making the bot’s responses smoother and more coherent.

Web Scraping
What is web scraping and how is it used in my Gen AI?
Web scraping is a method we use to gather relevant data from web pages you specify as data sources in your knowledge base. This enriches your Gen AI with up-to-date information from the web.
Can we scrape any web page on the web?
While our goal is to scrape a broad range of web pages, some restrictions apply. Some websites have anti-scraping mechanisms, and certain FAQ sections that require interaction to view answers may pose challenges. We recommend you test different web pages and examine the scraped data for compatibility. Rest assured, we're continually enhancing our scraping capabilities and plan to introduce additional libraries in the near future.
How to deal with intranet web pages?
Scraping content from intranet pages is more complex, but we offer several options:
- You can send us content through an API using a relay script within your intranet.
- Depending on your IT policy, a reverse proxy could be configured to securely route intranet content to our scraper.
What are the available options for web scraping?
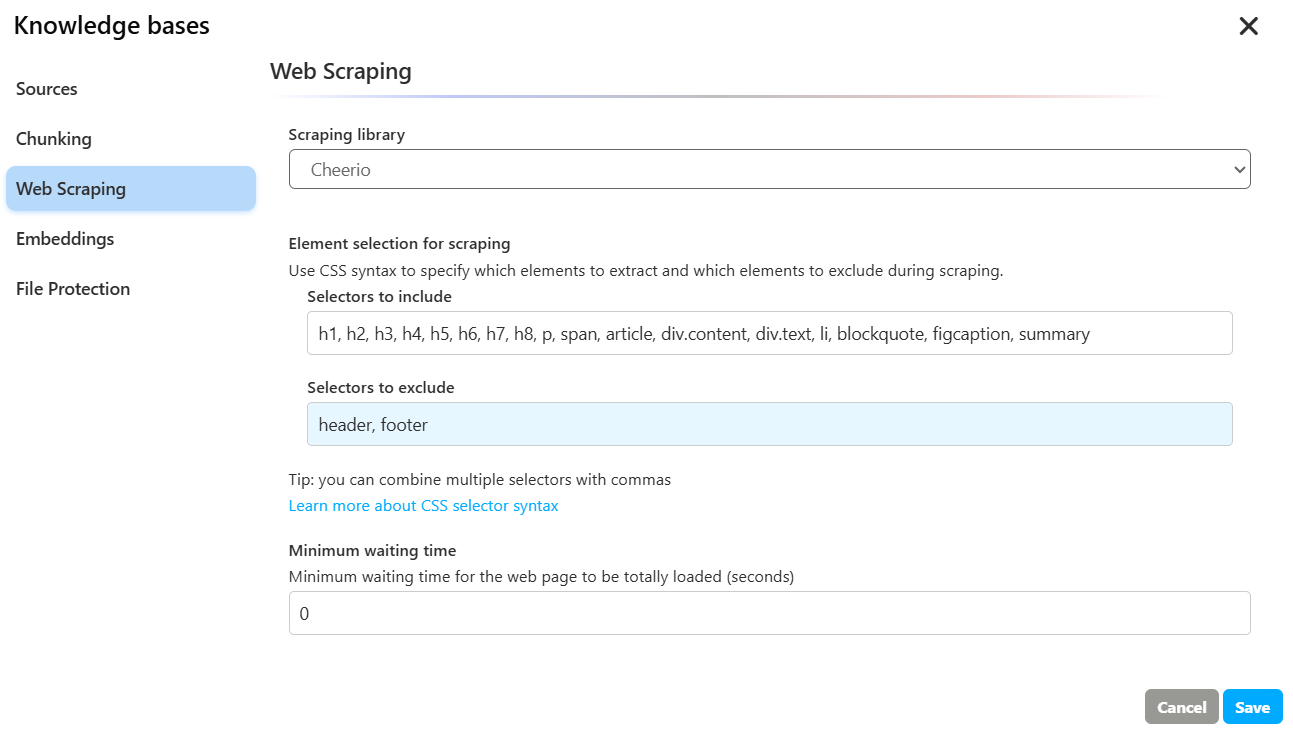
Here are the options you can choose from, and when to use each:
-
Cheerio (HTML parsing)
- Best for:
- Static pages where HTML is fully returned by the server.
- High-throughput, low-cost scraping (fast and lightweight).
- Simple extraction from blogs, documentation, news, or sitemap-linked pages.
- Pros:
- Very fast and resource efficient.
- Low maintenance and easier to scale.
- Cons:
- Cannot execute JavaScript. Won’t see content loaded dynamically by client-side frameworks (React/Vue/Angular).
- Use it when:
- You can fetch the final HTML via a simple HTTP GET.
- The content you need is visible in the page source or in static endpoints (RSS, JSON API, sitemap).
- You want to minimize cost and complexity.
- Tip:
- If some parts are missing, check if the page calls a JSON API you can query directly.
- Best for:
-
Puppeteer (headless browser automation)
- Best for:
- Dynamic or SPA sites where content is rendered by JavaScript after load.
- Pages that require user interaction (click, scroll, form submit) or login sessions.
- Scraping behind infinite scroll, pagination buttons, or cookie walls.
- Pros:
- Executes JavaScript, renders the page like a real browser.
- Can handle waits, selectors, screenshots, and complex flows.
- Cons:
- Heavier, slower, and more expensive to run at scale.
- More sensitive to anti-bot protections (may need human-like delays, retries, proxies).
- Use it when:
- Cheerio returns incomplete content because the page builds content client-side.
- You need to simulate user actions or wait for elements to load.
- The site requires authentication or complex navigation.
- Best for:
Recommended decision path
- Start with Cheerio:
- Works in most cases for static pages.
- Faster, cheaper, simpler.
- Switch to Puppeteer if:
- Content doesn’t appear in page source.
- You see placeholders like “Loading…” or empty containers until JS runs.
- You must click, scroll, or log in to reveal content.
Embeddings
Embeddings are the technical process that transforms your texts into numerical vectors, allowing the AI to understand meaning and semantic similarity. In this section, you need to select the AI Deployment (AI model) that will be specifically used to generate these embeddings. The choice of model can affect the quality of semantic search.

File Protection
This option is crucial for the security and confidentiality of your internal documents.
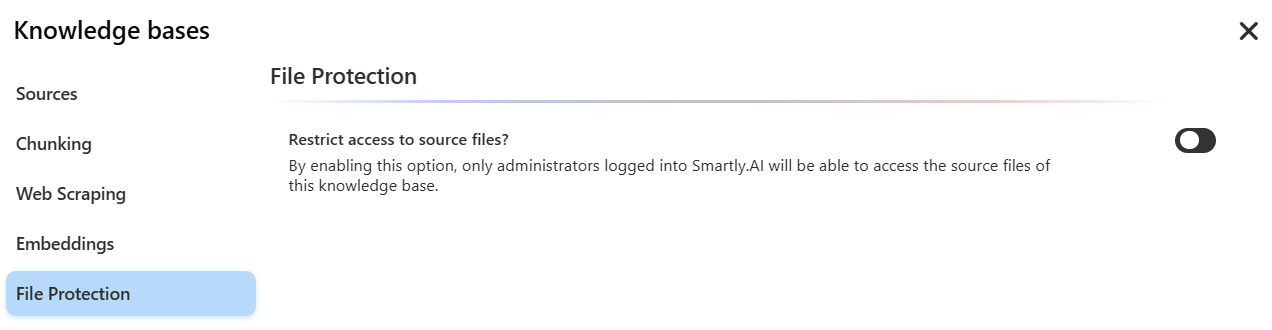
By enabling the Restrict access to source files? option, only administrators logged into the Smartly.AI platform will be able to access the original files of this knowledge base. This prevents the bot from generating and providing direct download links to your documents in its responses to the public. The bot will use the content of the documents to answer questions but will never share the files themselves.
Indexation
What is indexation?
Indexation prepares your knowledge base so your assistant can quickly search and retrieve answers. It includes ingestion, cleaning, splitting, vectorization, and storage.
When is indexation needed?
Re-index whenever:
- KB settings are updated,
- KB content is changed, or
- linked external sources (like websites) may have changed.
👉 The dashboard will highlight when indexation is required.
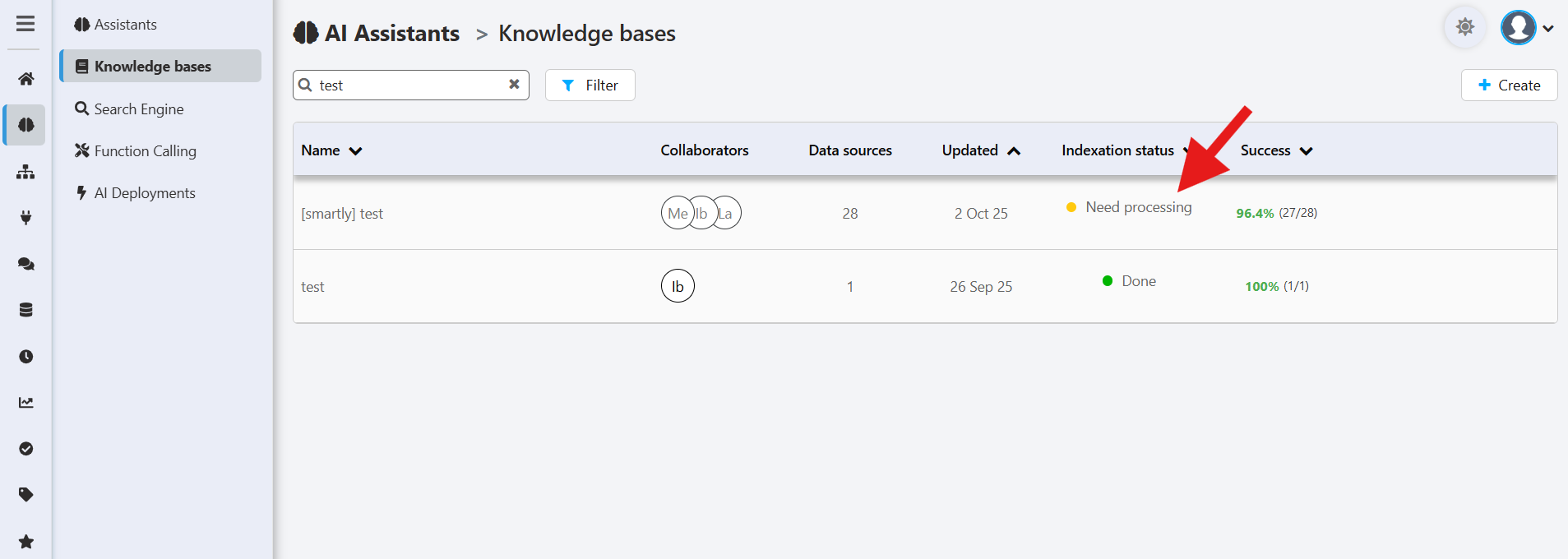
How to start indexation
Click the Index button next to your assistant. A progress popup will appear and confirm when complete.
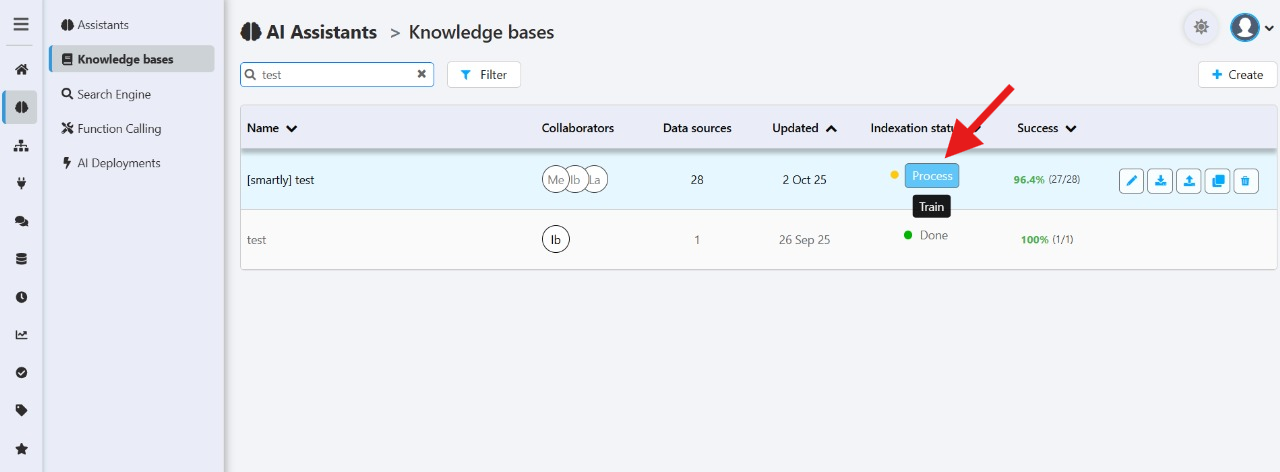
Tracking progress
A popup will display the progress and confirm once indexation is complete.
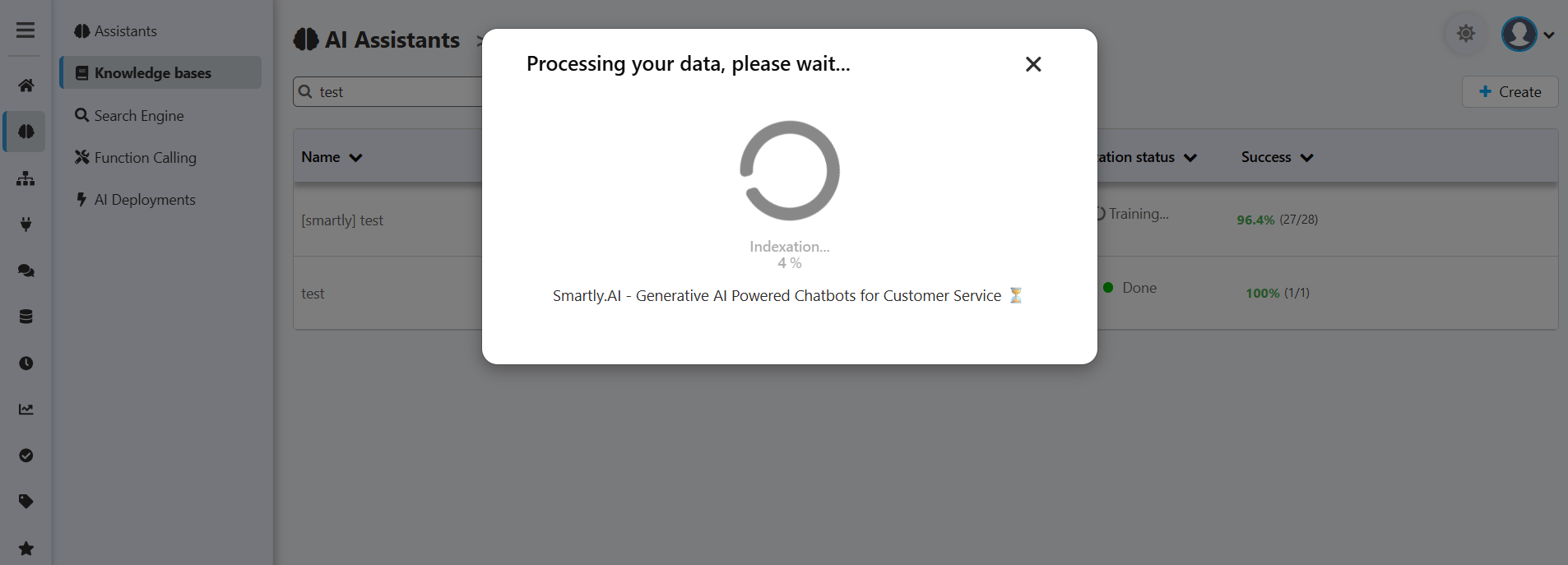
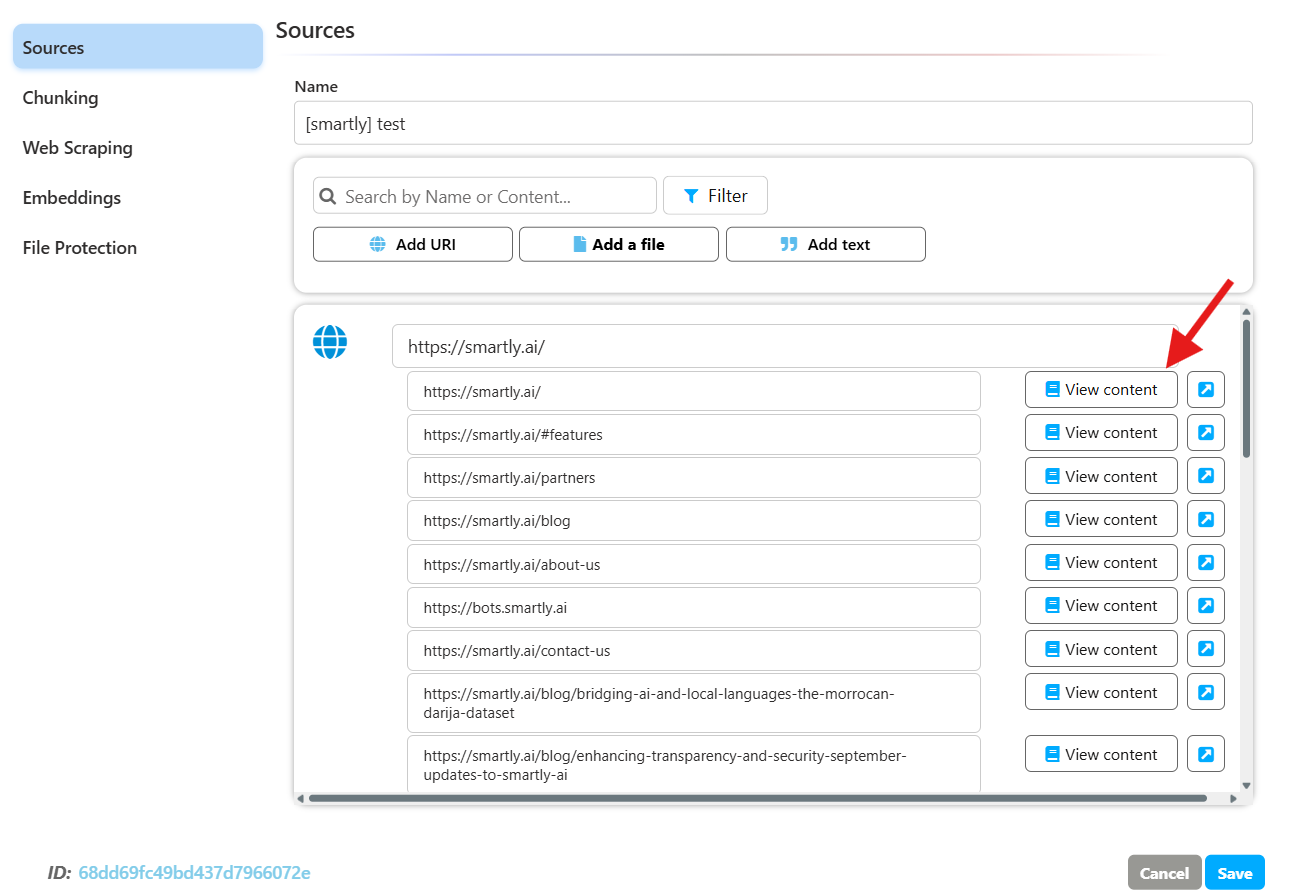
After indexation
- Review content chunks inside each data source (via View Content).
- Refine scraping and chunking settings until the KB looks right.
- Attach the KB to your assistant.
Your assistant is now ready for testing and production.
Attach the Knowledge Base to Your Assistant
Once your knowledge base is created and indexed, don’t forget the final step: attach it to your AI Assistant in the assistant’s settings so it can start using it.
Updated 10 months ago