Beyond Naive RAG
When it comes to AI assistants, not all solutions are created equal. Many rely on what we refer to as a "naive RAG" (Retrieval-Augmented Generation) approach, which often involves little more than fetching documents and feeding them directly into a language model for response generation. While this approach can work for simple queries, it falls short in complex, real-world scenarios where precision, efficiency, and scalability are crucial.
At Smartly.AI, we’ve built a more advanced architecture to ensure our assistants deliver accurate, contextually relevant, and actionable responses. Here’s a breakdown of our pipeline:
1. Input Sanitization Stage
Before anything else, user inputs are cleansed to remove noise, standardize formats, and handle prompts injection techniques. This ensures the system starts with a clean, well-structured input, improving downstream processes.
2. Query Condensation
User queries can be verbose or contain unnecessary information. In this step, we simplify these inputs by extracting the essential intent and key details. This reduces ambiguity and focuses on the critical components for more accurate retrieval and generation.
For example:
User: "I want to buy an apartment."
Assistant: "Awesome! Where?"
User: "In New York."
Assistant: "How many rooms do you need? How many square meters?"
User: "120 sqm, 3 rooms."
Condensed query: "I want to buy a 3-room, 120 sqm apartment in New York."
3. Query Variabilization
In this step, the condensed query is expanded into variations that consider synonymous terms, alternative phrasing, or contextual relevance. This ensures the assistant can retrieve the most relevant data, even if it's worded differently in the documents.
4. Document Search
With the refined query, our system performs a targeted search across the knowledge base. Unlike naive RAG systems that consider the entire document set, our approach narrows the search to the most relevant knowledge base. This minimizes confusion and ensures more accurate results. We also enhance our search by combining semantic and keyword search techniques, enabling us to efficiently locate the most contextually relevant documents.
5. Document Filtering
Once documents are retrieved, we filter out irrelevant or redundant data. We keep only the top N documents that have a similarity score above a predefined threshold, ensuring that only the most pertinent information is passed on to the next stage.
6. Answer Generation
Here, the refined query and filtered documents are used to generate a coherent, contextually accurate response. This stage leverages a language model but with structured inputs from previous stages, enhancing its reliability, also if there is some functions/tools defined, we present them to the LLM.
7. Function Calling (if applicable)
In some cases, generating the best response requires executing specific actions, such as API calls or database queries. This step integrates external functions and loops back into the generation stage to incorporate results into the final response.
8. Post-Processing
Finally, the response undergoes a post-processing stage where we ensure clarity, correctness, and alignment with the user’s intent. This includes formatting, consistency checks, and injecting personalization if necessary.
9. Logging and Observability
To ensure continuous improvement and full observability, all interactions and processing details are logged. These logs are invaluable for analyzing patterns, diagnosing issues, and providing transparency for auditing purposes. They also allow us to track the assistant's performance over time and make data-driven enhancements.
The following screenshot shows the observability feature in the Smartly.ai platform. We can see for each assistant answer, each step, its inputs and ouputs as well as the token consumption and the system prompt.
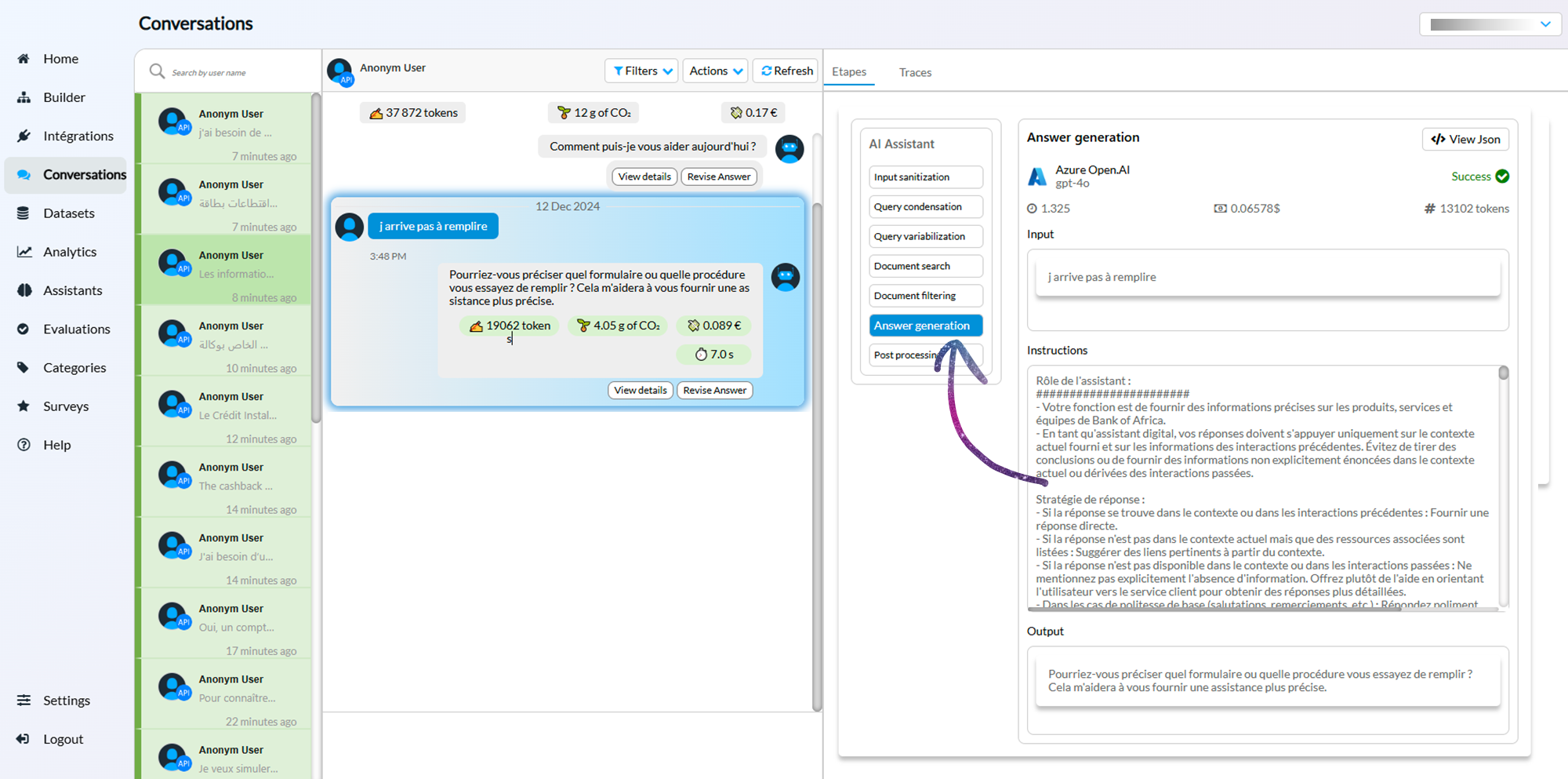
Observability in Smartly.AI
Why This Pipeline is Superior
Unlike naive RAG systems, which rely on simplistic document retrieval and generation, our approach introduces multiple layers of refinement, feedback, and optimization. This pipeline ensures:
- Higher Precision: By condensing and variabilizing queries, we avoid irrelevant or misleading results.
- Improved Scalability: Intelligent filtering and structured steps prevent the model from being overwhelmed by irrelevant data.
- Actionable Insights: Function calling extends the assistant’s capabilities beyond simple Q&A, enabling dynamic actions and integrations.
- Reliable Output: Post-processing guarantees responses meet a high standard of quality and relevance.
- Continuous Improvement: Logging and observability provide the tools needed to refine the assistant and maintain transparency.
The following flowcharts compare the features of the naive RAG approach and Smartly.AI's advanced pipeline.
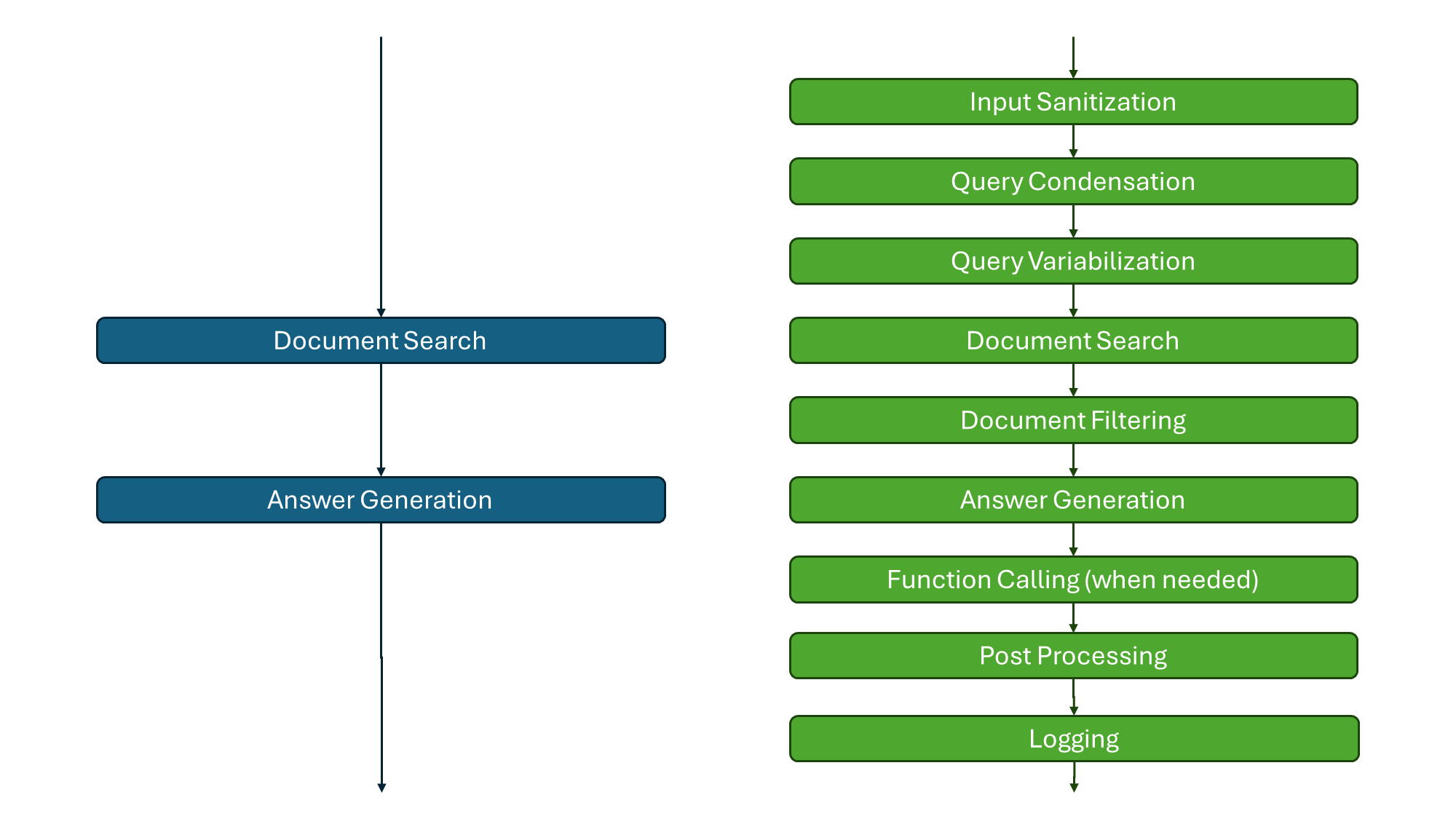
Naive RAG (left) vs Smartly's pipeline (right)
In short, this pipeline transforms the assistant into a robust, enterprise-grade solution capable of handling complex, dynamic, and high-stakes interactions. Naive RAG systems can’t compete with this level of precision and adaptability.
Updated 10 months ago