April 2026
Version 3.32.1
Released on April 21st, 2026
✨ New Feature
-
New: Sensitive Data Exclusion for API Dialog Implementation of a memory field exclusion filter within the dialogue management settings. This feature allows for the selection of specific or all fields from Shared Memory, Long Term Memory, and Short Term Memory to be removed from the API Dialog response. This enhancement ensures the protection of sensitive data, such as authentication tokens or internal identifiers, by preventing their exposure in external API calls.
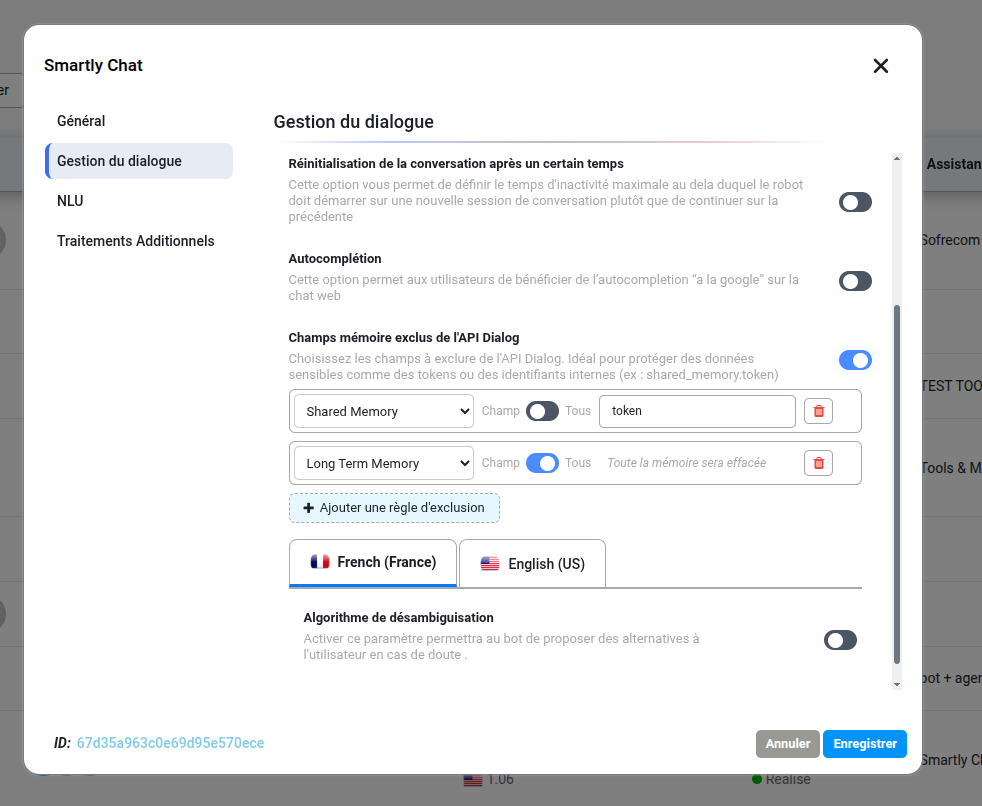
UI / UX Enhancements
- Improved: Translation Configuration Interface Layout Reorganization of the “Additional Processings” section in the skill settings for a more logical navigation flow. The Skip Language Detection toggle has been moved directly under the Translate the bot response section, and the Regional Languages & Dialects Support options are now positioned at the end of the module for a more intuitive setup experience.
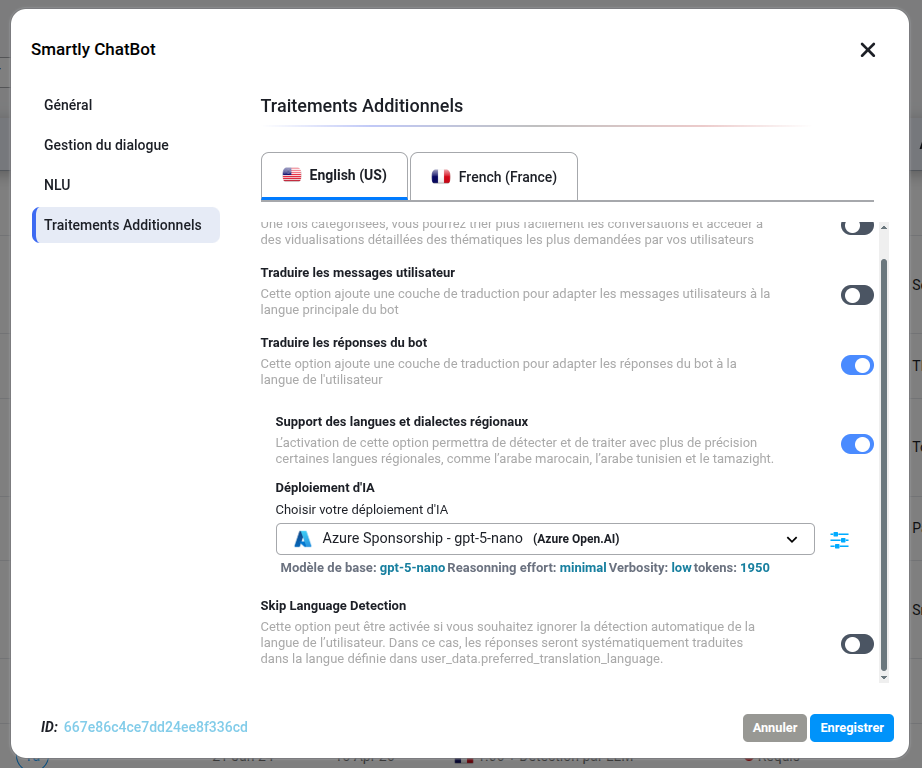
Bug Fixes
-
Fixed: Internal Server Error during large conversation exports Resolved an issue causing an internal server error when exporting full conversation history for high-volume bots.
-
Fixed: Mobile UI Responsiveness for Voice & Language Selection
Resolution of layout and accessibility issues on specific mobile screen sizes. The language selection menu is now fully accessible, and the microphone (Voice Chat) button visibility has been corrected to ensure a consistent user experience across all mobile devices.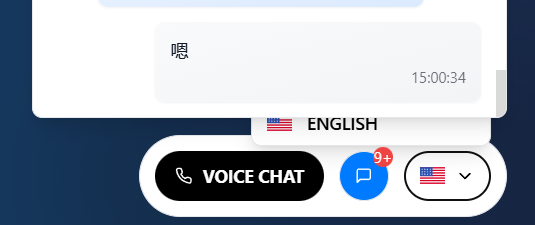
-
Fixed: Dynamic Chunking for .TXT Documents Resolution of a bug preventing the dynamic chunking engine from correctly segmenting content within .txt files during the indexing process.
-
Fixed: Concurrent Document Upload Issues Resolution of a stability issue encountered when uploading multiple documents simultaneously to a Knowledge Base.
-
Fixed: Message visibility in conversations Some messages from rich messages were not displayed in the conversation module due to a non-compliant data format. Processing has been added to ensure they are displayed correctly.
-
Fixed: Collaboration synchronization issue Collaborators linked to AI deployments are not synchronized following changes made from the assistant or from the skill settings (translation, categorization, Additional NLU). Additionally, updates to tools or MCPs in the assistant are not reflected in the associated collaborators.
Version 3.32.0
Released on April 1st, 2026
✨ New Feature & Enhancements
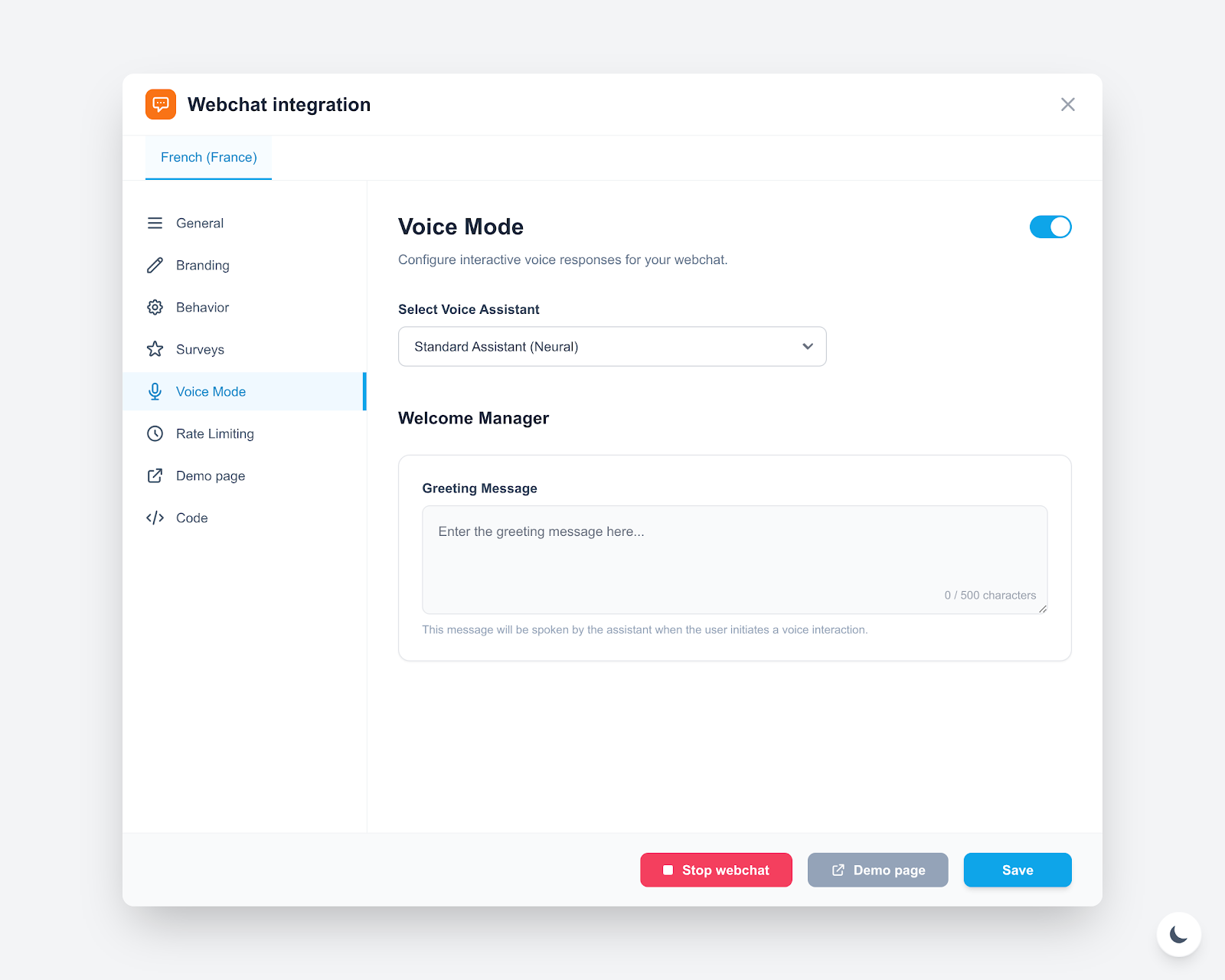
New: Voice Mode for Webchat Integration
Introduction of a dedicated Voice Mode within the Webchat configuration. This feature allows assistants to engage in interactive voice conversations.
- Select Voice Assistant: Choose a specific neural voice model for the integration.
- Welcome Manager: Configure a custom spoken greeting message that triggers when the voice session starts.
New: Base Model Customization in Realtime Mode
Addition of the ability to modify the base model when using the Realtime(Chat Completion) API mode within LLM Proxy. This provides greater flexibility for selecting and swapping underlying models while maintaining low-latency streaming interactions.
🛡️ Platform & Engine Reliability
- Improved: Execution Timeouts Calibration
- Reduction of the Node.js code execution timeout to 60s (previously 90s/120s) to optimize resource allocation. A notification message has been added to the Node.js editor to inform users of this constraint during the save process.
- Adjustment of the Zeus engine timeout to 8s for classical NLU operations, ensuring faster response times.
🐞 Bug Fixes
-
Fixed: Intent Prioritization in Hybrid NLU & Microbot Architectures Resolution of intent selection conflicts when the same intent exists across multiple microbots or the masterbot. The Hybrid NLU engine now follows a strict prioritization logic:
- Contextual Priority: Intents matching the current active context are prioritized.
- Response Linkage: Intents associated with a defined bot response are favored over unlinked intents.
- Local Priority: Preference is given to the masterbot or the current microbot to ensure conversational consistency.
-
Fixed: Hybrid NLU Embedding Configuration Synchronization
Resolution of a persistence issue where the Hybrid NLU engine would continue to use legacy embedding configurations after the linked AI Deployment model was updated. The system now ensures that any change to the deployment model is automatically reflected in the Hybrid NLU’s vectorization process, maintaining consistency across the RAG pipeline.